
코딩로그
9. Neural Network 1: XOR 문제와 학습방법, Backpropagation 본문
<XOR문제 딥러닝으로 풀기>
-
지난시간에 여러개의 logistic regression unit을 통해 xor문제를 풀 수 있다고 했다. 그런데 정말 가능할까? 증명해보자.
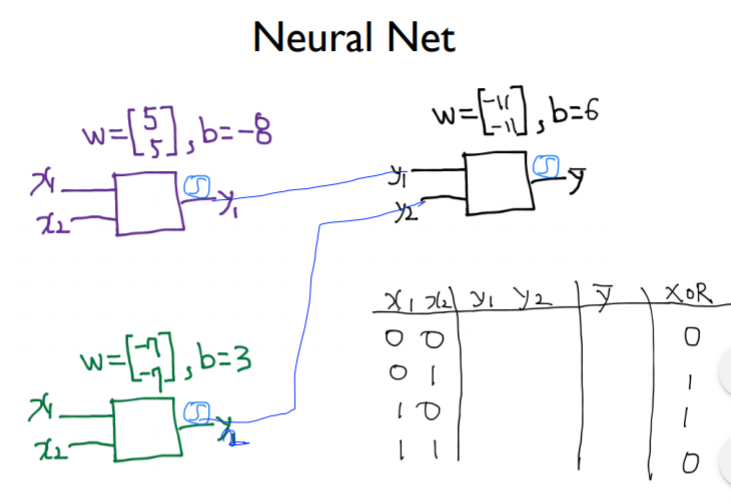
-
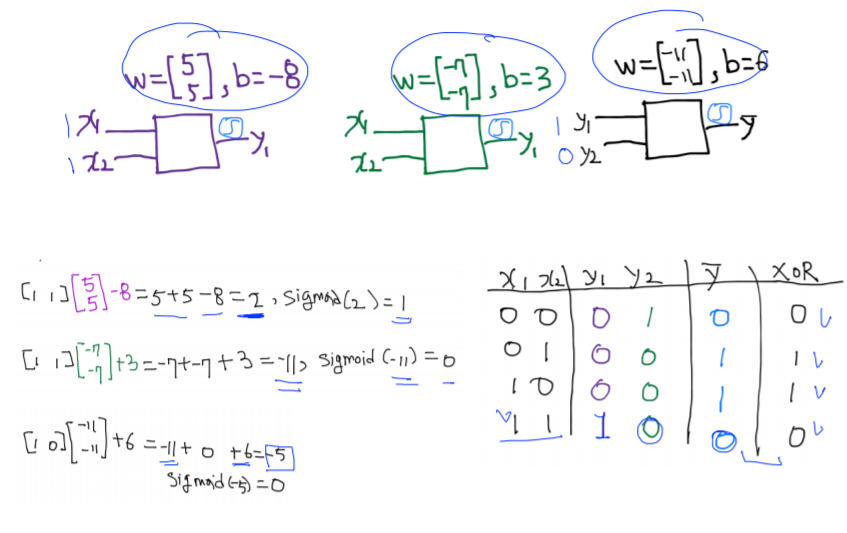
그림과 같이 임의로 w와 b의 값을 지정한 3개의 unit이 있다고 할 때, 왼쪽의 unit두개의 출력이 오른쪽 unit의 입력값이 되는 neural net을 구성해보았다. 이를 통해 XOR문제를 해결해보자.
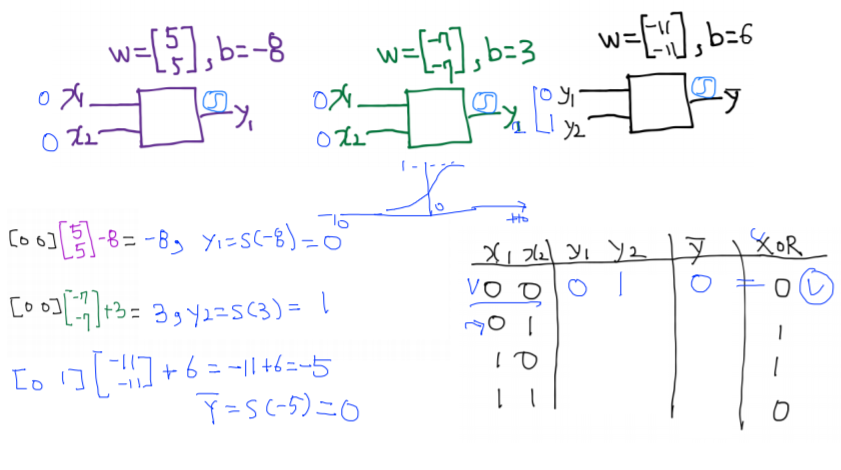
- 첫 번째 unit : wx+b에 의해 –8이라는 값이 나오고, sigmoid함수의 경우 값이 작을수록 0에 수렴한다. 따라서 sigmod함수를 거친 결과 첫 번째 unit의 결과값은 대략 0이다.
- 두 번째 unit : wx+b에 의해 3이라는 값이 나오고, sigmoid함수의 경우 값이 클수록 1에 수렴한다. 따라서 sigmod함수를 거친 결과 첫 번째 unit의 결과값은 대략 1이다.
- 세 번째 unit : 위와 같은 과정을 거쳐 0이라는 값이 나온다. 그결과는 xor의 결과와 일치한다.
-
위의 과정을 반복해 다양한 입력에 대해 결과값을 예측해보았다.
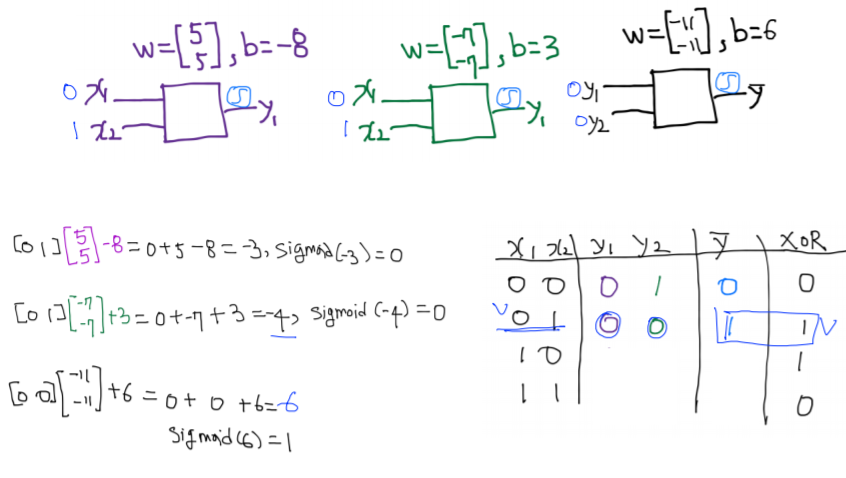
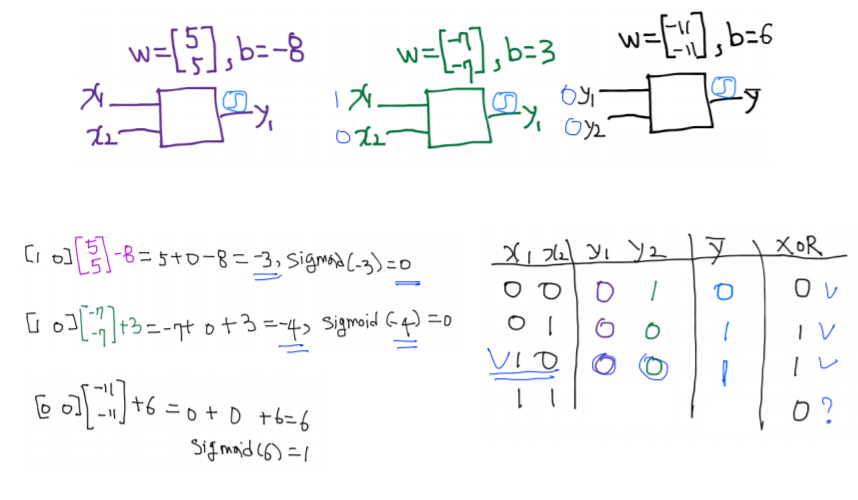
-
그 결과 위와 같이 model이 잘 작동함을 알 수 있다.
-
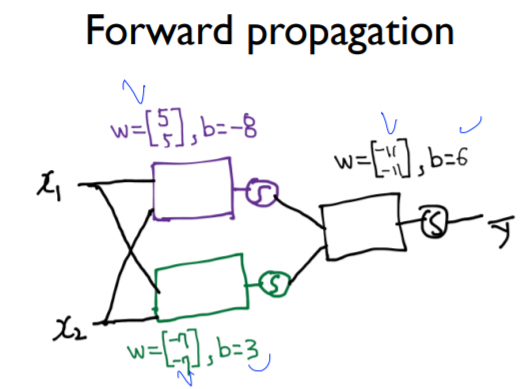
또한, 모델을 위와 같이 나타낼 수 있다.
-
상단의 계산 과정은 x1과 x2에서 입력이 시작되어 오른쪽의 y에 도달하는 순전파라고 할 수 있다.
-
그림을 보면 한 층에 두개의 unit이 있는데, 필자의 경우 이걸 어떻게 code로 나타낼 지 정말 궁금했다.
-
해결을 위해서는 행렬을 이용하면 된다 ! 다음과 같이 두개의 unit을 하나로 묶어 나타낼 수 있다.(w와 b의 rank는 늘어난다.)
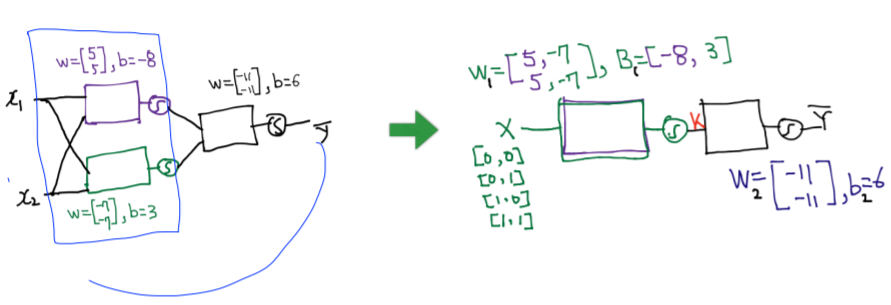
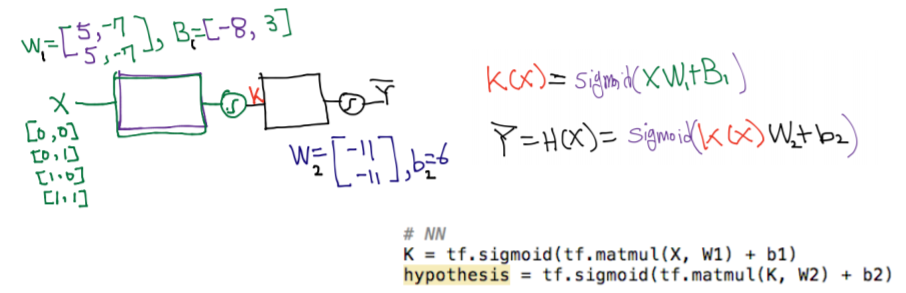
<실습1. XOR을 위한 텐스플로우 딥넷트웍>
- 기존의 logistic regression을 이용한 코드 -> 작동하지 않는다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
tf.set_random_seed(777)
x_data = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=np.float32)
y_data = np.array([[0],[1],[1],[0]], dtype=np.float32)
X = tf.placeholder(tf.float32, [None, 2])
Y = tf.placeholder(tf.float32, [None, 1])
#in->x1,x2 두개, out-> y 하나 따라서 [2,1]
W = tf.Variable(tf.random_normal([2,1]), name = "weight")
#b의 형태는 언제나 out의 형태와 같음 -> [1]
b = tf.Variable(tf.random_normal([1]), name = "bias")
hypothesis = tf.sigmoid(tf.matmul(X,W)+b)
# local minimum에 빠지지 않도록 !
cost = tf.reduce_mean(Y*tf.log(hypothesis)+(1-Y)*tf.log(1-hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
#hypothesys>0.5 true(1) else false(0) ->cast함수가 함
predicted = tf.cast(hypothesis>0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted,Y), dtype = tf.float32))
with tf.Session() as sess:
#Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cost_val, w_val = sess.run(
[train, cost, W], feed_dict = {X: x_data, Y: y_data}
)
if step %100 ==0:
print(step, cost_val, w_val)
#Accuracy report
h, c, a = sess.run(
[hypothesis, predicted, accuracy], feed_dict={X:x_data, Y:y_data}
)
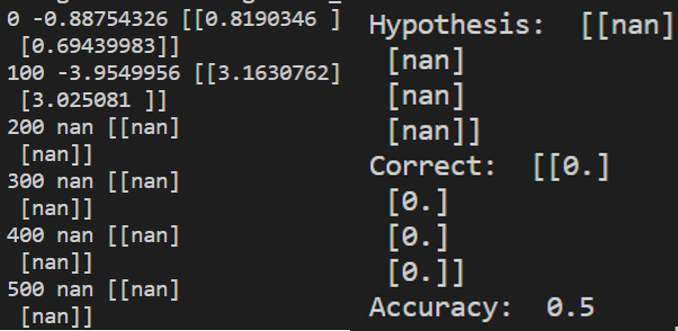
print("\nHypothesis: ", h, "\nCorrect: ", c, "\nAccuracy: ", a)
|
cs |
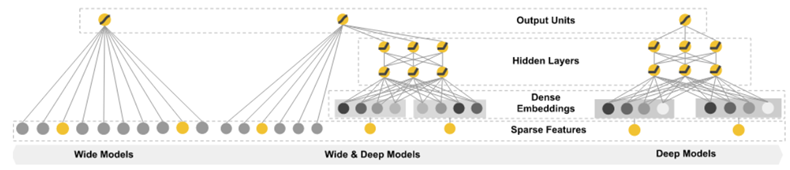
- 신경망 계층을 2개로 한 것, 계층이 2개인 신경망을 wide하게 한 것, wide&deep한 신경망을 만들어보았다. 다음 그림을 보면 이해하기가 쉬울 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
tf.set_random_seed(777)
x_data = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=np.float32)
y_data = np.array([[0],[1],[1],[0]], dtype=np.float32)
X = tf.placeholder(tf.float32, [None, 2])
Y = tf.placeholder(tf.float32, [None, 1])
#//레이어 없이//#
#in->x1,x2 두개, out-> y 하나 따라서 [2,1]
#W = tf.Variable(tf.random_normal([2,1]), name = "weight")
#b의 형태는 언제나 out의 형태와 같음 -> [1]
#b = tf.Variable(tf.random_normal([1]), name = "bias")
#hypothesis = tf.sigmoid(tf.matmul(X,W)+b)
#-> 작동하지 않는다.
#//층하나를 만듦//#
#지난시간에 두개의 유닛을 행렬을 통해 하나로 합친다고 했었죠?
#unit -> w shape([1,2]), b shape([1]) 둘이 합쳐져서 밑과 같습니다.
#어려우면 그냥 in이 2이고, 두개의 유닛이기 때문에 out도 2이다라고 이해해도 괜찮습니다.
#W1 = tf.Variable(tf.random_normal([2,2]), name = 'weight1')
#b1 = tf.Variable(tf.random_normal([2]), name = 'bias1')
#layer1 = tf.sigmoid(tf.matmul(X,W1)+b1)
#W2 = tf.Variable(tf.random_normal([2,1]), name = 'weight2')
#b2 = tf.Variable(tf.random_normal([1]), name = 'bias2')
#hypothesis = tf.sigmoid(tf.matmul(layer1,W2)+b2)
#//wide model//#
#하나의 층에서 unit을 여러개로 만드는 것 = 출력을 여러개로 만드는 것
#W1 = tf.Variable(tf.random_normal([2,10]), name = 'weight1')
#b1 = tf.Variable(tf.random_normal([10]), name = 'bias1')
#layer1 = tf.sigmoid(tf.matmul(X,W1)+b1)
#W2 = tf.Variable(tf.random_normal([10,1]), name = 'weight2')
#b2 = tf.Variable(tf.random_normal([1]), name = 'bias2')
#hypothesis = tf.sigmoid(tf.matmul(layer1,W2)+b2)
#//wide&deep model//#
W1 = tf.Variable(tf.random_normal([2, 10]), name='weight1')
b1 = tf.Variable(tf.random_normal([10]), name='bias1')
layer1 = tf.sigmoid(tf.matmul(X, W1) + b1)
W2 = tf.Variable(tf.random_normal([10, 10]), name='weight2')
b2 = tf.Variable(tf.random_normal([10]), name='bias2')
layer2 = tf.sigmoid(tf.matmul(layer1, W2) + b2)
W3 = tf.Variable(tf.random_normal([10, 10]), name='weight3')
b3 = tf.Variable(tf.random_normal([10]), name='bias3')
layer3 = tf.sigmoid(tf.matmul(layer2, W3) + b3)
W4 = tf.Variable(tf.random_normal([10, 1]), name='weight4')
b4 = tf.Variable(tf.random_normal([1]), name='bias4')
hypothesis = tf.sigmoid(tf.matmul(layer3, W4) + b4)
# local minimum에 빠지지 않도록 !
cost = -tf.reduce_mean(Y*tf.log(hypothesis)+(1-Y)*tf.log(1-hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
#hypothesys>0.5 true(1) else false(0) ->cast함수가 함
predicted = tf.cast(hypothesis>0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted,Y), dtype = tf.float32))
with tf.Session() as sess:
#Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
_, cost_val, = sess.run([train, cost], feed_dict = {X: x_data, Y: y_data})
if step %100 ==0:
print(step, cost_val)
#Accuracy report
h, p, a = sess.run([hypothesis, predicted, accuracy], feed_dict={X:x_data, Y:y_data} )
print("\nHypothesis: ", h, "\nCorrect: ", p, "\nAccuracy: ", a)
|
cs |
'코딩로그 > 모두를 위한 딥러닝' 카테고리의 다른 글
| 11. Convolutional Neural Networks (0) | 2020.02.01 |
|---|---|
| 10. Neural Network 2: ReLU and 초기값 정하기 (0) | 2020.02.01 |
| 8. 딥러닝의 기본 개념과, 문제, 그리고 해결 (0) | 2020.01.11 |
| 7-2. ML의 실용 : mnist data set 실습 (0) | 2020.01.11 |
| 7-1. ML의 실용과 몇가지 팁 (0) | 2020.01.11 |



