
코딩로그
6. softmax regression 본문
- 지난시간에는 두가지의 값으로 분류하는 binary classification에 대해 배웠다.
- 이번시간에는 여러가지 값으로 분류하는 multinomial classification에 대해 알아보겠다.
<Softmax regression>
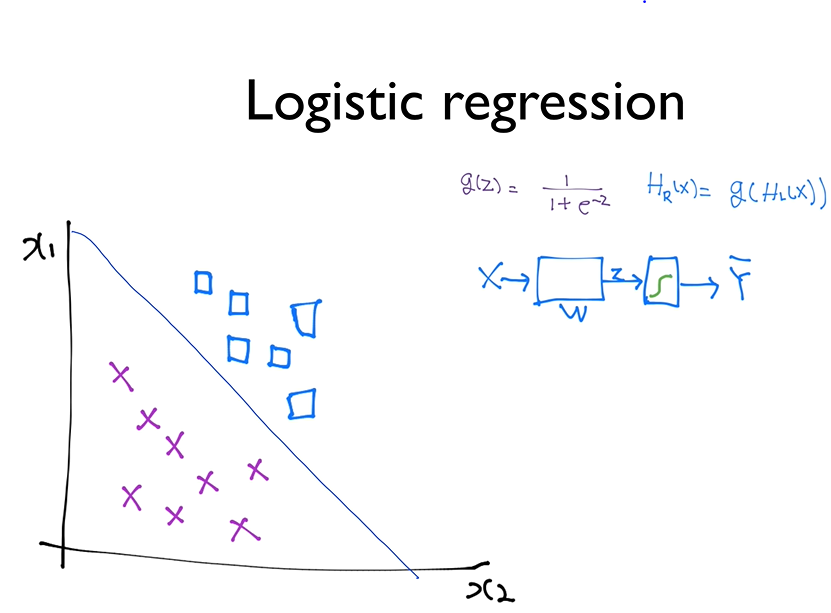
이전에는 위의 그림과 같이 하나의 선으로 두종류의 데이터를 분류하는 방법에 대해 배웠다.
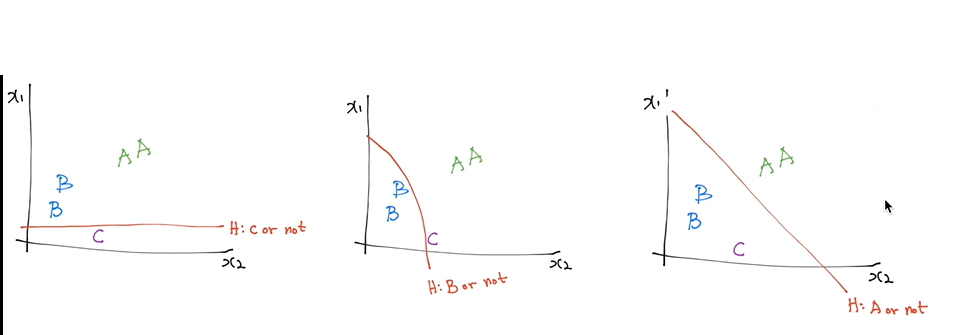
이와 같이 세개의 선을 사용함으로써 세개 이상의 값도 분류해낼 수 있다.
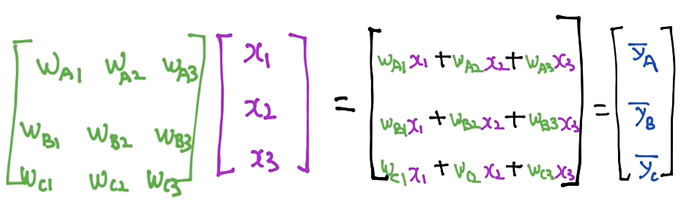
세개의 선을 각각 나타내지 않고 위와 같이 행렬로 나타낼 수 있다.
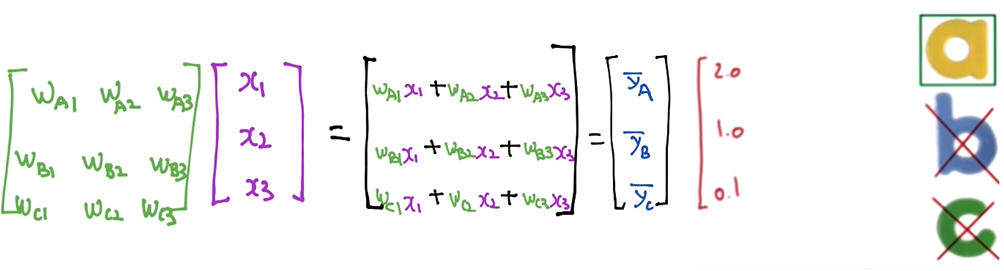
hypothesis에 따라 여기에 해당하는 $\bar{y}_{a},\bar{y}_{b}, \bar{y}_{c}$가 나올 것이다. 위 그림의 경우에서는 당연히 a가 답이 될 것이다.
- 그런데 값을 확률로 나타내고 싶을 수 있다. a가 될 확률, b가 될 확률, c가 될 확률를 합쳐 그 합이 1이 되도록 말이다. 이를 가능하게 하는 것이 바로 softmax 함수이다.
softmax 함수를 통해 각각의 확률을 알아낸 뒤, numpy의 argmax를 이용해 가장 큰 값에는 1을, 나머지 값에는 0을 주고, 이를 통해 결과값을 예측한다.
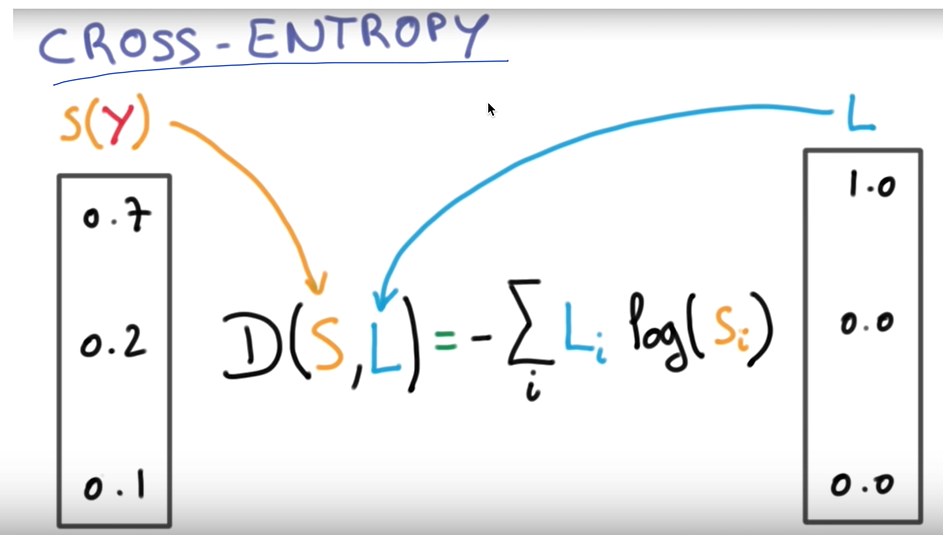
학습 데이터와 실제 데이터를 비교하는 방법 중 cross-entropy라는 방법도 있다.
위의 이미지와 같이 S를 학습 데이터, L을 실제 데이터라 할때, cross-entropy는 $\ D\left ( S,L \right ) = -\sum_{i}L_{i}log(S_{i})$이다.
결론적으로 보았을 때는 이전에 logistic regression에서의 cost-function과 같은 기능을 한다. 그 이유는 다음과 같다.
- L, S에 관한 sum으로 정의되는데 크로스 엔트로피에서 L의 sum은 항상 1이 되며, cost함수의 우측 term은 0이된다. 그래서 cost function과 cross-entropy가 같다.
<실습1 - softmax classification 구현>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
|
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
x_data = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
# one-hot incoding으로 표시
y_data = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0],
[0, 1, 0],
[0, 1, 0],
[1, 0, 0],
[1, 0, 0]]
X = tf.placeholder("float", [None, 4])
Y = tf.placeholder("float", [None, 3])
nb_classes = 3
W = tf.Variable(tf.random_normal([4, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
# **softmax = exp(logits) / reduce_sum(exp(logits), dim)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(2001):
_, cost_val = sess.run([optimizer, cost], feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, cost_val)
print('--------------')
# Testing & One-hot encoding
a = sess.run(hypothesis, feed_dict={X: [[1, 11, 7, 9]]})
print(a, sess.run(tf.argmax(a, 1)))
print('--------------')
b = sess.run(hypothesis, feed_dict={X: [[1, 3, 4, 3]]})
print(b, sess.run(tf.argmax(b, 1)))
print('--------------')
c = sess.run(hypothesis, feed_dict={X: [[1, 1, 0, 1]]})
print(c, sess.run(tf.argmax(c, 1)))
print('--------------')
all = sess.run(hypothesis, feed_dict={X: [[1, 11, 7, 9], [1, 3, 4, 3], [1, 1, 0, 1]]})
print(all, sess.run(tf.argmax(all, 1)))
'''
0 3.277706
200 0.55693114
400 0.453861
600 0.37724543
800 0.30550602
1000 0.23968634
1200 0.21589793
1400 0.19694954
1600 0.18097109
1800 0.16731781
2000 0.15552174
--------------
[[4.4052387e-03 9.9558359e-01 1.1202120e-05]] [1]
--------------
[[0.8675848 0.11492327 0.01749188]] [0]
--------------
[[1.5362906e-08 3.6404340e-04 9.9963593e-01]] [2]
--------------
[[4.40523867e-03 9.95583594e-01 1.12021198e-05]
[8.67584765e-01 1.14923365e-01 1.74918864e-02]
[1.53629056e-08 3.64043401e-04 9.99635935e-01]] [1 0 2]
'''
|
cs |
<실습2 - Fancy softmax classification 구현>
- cross_entropy, one_hot에 대해 더 알아보고, reshape를 통해 모양을 더 예쁘게 만들어보자.
- 실습1에서의 cross_entropy cost function을 실습 2에서는 다른 함수를 이용해 더 간단하게 만든다.
- 레이블의 값을 나타내는 y를 one-hot 함수와 reshape를 통해 one-hot-encoding 형태로 바꾼다.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485import tensorflow.compat.v1 as tftf.disable_v2_behavior()import numpy as np# Predicting animal type based on various featuresxy = np.loadtxt('data-04-zoo.csv', delimiter=',', dtype=np.float32)x_data = xy[:, 0:-1]y_data = xy[:, [-1]]nb_classes = 7 # 0 ~ 6X = tf.placeholder(tf.float32, [None, 16])Y = tf.placeholder(tf.int32, [None, 1]) # 0 ~ 6, shape(?,1)Y_one_hot = tf.one_hot(Y, nb_classes) # one hot, shape(?,1,7) one-hot function은 한 차원을 더해준다.Y_one_hot = tf.reshape(Y_one_hot, [-1, nb_classes]) # shape(?,7) 따라서 reshape가 필요하다.W = tf.Variable(tf.random_normal([16, nb_classes]), name='weight')b = tf.Variable(tf.random_normal([nb_classes]), name='bias')# tf.nn.softmax computes softmax activations# softmax = exp(logits) / reduce_sum(exp(logits), dim)logits = tf.matmul(X, W) + bhypothesis = tf.nn.softmax(logits)# **달라진 부분 Cross entropy cost/losscost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,labels=tf.stop_gradient([Y_one_hot])))optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)prediction = tf.argmax(hypothesis, 1)correct_prediction = tf.equal(prediction, tf.argmax(Y_one_hot, 1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))# Launch graphwith tf.Session() as sess:sess.run(tf.global_variables_initializer())for step in range(2001):_, cost_val, acc_val = sess.run([optimizer, cost, accuracy], feed_dict={X: x_data, Y: y_data})if step % 100 == 0:print("Step: {:5}\tCost: {:.3f}\tAcc: {:.2%}".format(step, cost_val, acc_val))# Let's see if we can predictpred = sess.run(prediction, feed_dict={X: x_data})# y_data: (N,1) = flatten => (N, ) matches pred.shapefor p, y in zip(pred, y_data.flatten()):print("[{}] Prediction: {} True Y: {}".format(p == int(y), p, int(y)))'''Step: 0 Cost: 5.355 Acc: 7.92%Step: 100 Cost: 0.602 Acc: 81.19%Step: 200 Cost: 0.376 Acc: 87.13%Step: 300 Cost: 0.273 Acc: 90.10%Step: 400 Cost: 0.215 Acc: 99.01%Step: 500 Cost: 0.178 Acc: 99.01%Step: 600 Cost: 0.152 Acc: 99.01%Step: 700 Cost: 0.132 Acc: 99.01%Step: 800 Cost: 0.117 Acc: 99.01%Step: 900 Cost: 0.105 Acc: 99.01%Step: 1000 Cost: 0.096 Acc: 99.01%Step: 1100 Cost: 0.088 Acc: 99.01%Step: 1200 Cost: 0.081 Acc: 99.01%Step: 1300 Cost: 0.075 Acc: 99.01%Step: 1400 Cost: 0.070 Acc: 99.01%Step: 1500 Cost: 0.065 Acc: 100.00%Step: 1600 Cost: 0.062 Acc: 100.00%Step: 1700 Cost: 0.058 Acc: 100.00%Step: 1800 Cost: 0.055 Acc: 100.00%Step: 1900 Cost: 0.052 Acc: 100.00%Step: 2000 Cost: 0.050 Acc: 100.00%[True] Prediction: 0 True Y: 0[True] Prediction: 0 True Y: 0[True] Prediction: 3 True Y: 3[True] Prediction: 0 True Y: 0[True] Prediction: 0 True Y: 0[True] Prediction: 0 True Y: 0[True] Prediction: 1 True Y: 1[True] Prediction: 0 True Y: 0[True] Prediction: 5 True Y: 5[True] Prediction: 0 True Y: 0[True] Prediction: 6 True Y: 6[True] Prediction: 1 True Y: 1'''cs
'코딩로그 > 모두를 위한 딥러닝' 카테고리의 다른 글
| 7-2. ML의 실용 : mnist data set 실습 (0) | 2020.01.11 |
|---|---|
| 7-1. ML의 실용과 몇가지 팁 (0) | 2020.01.11 |
| 5. logistic classification (0) | 2020.01.10 |
| *tip* TensorFlow로 파일에서 데이터 읽어오기 (0) | 2020.01.10 |
| 4. multi-variable linear regression을 TensorFlow에서 구현하기 (0) | 2020.01.04 |
'코딩로그/모두를 위한 딥러닝' Related Articles
more


